算法数珍
###1.树
####1. 前缀树
####2. 后缀树(Suffix Tree)
- 概述
后缀树(Suffix tree)是一种数据结构,能快速解决很多关于字符串的问题。后缀树的概念最早由Weiner 于1973年提出,既而由McCreight 在1976年和Ukkonen在1992年和1995年加以改进完善。
核心思想是通过构造母串的子串(后缀)压缩前缀树(Trie),来简化子串匹配和查找.例如字符串BANANA的后缀树构造图如下:
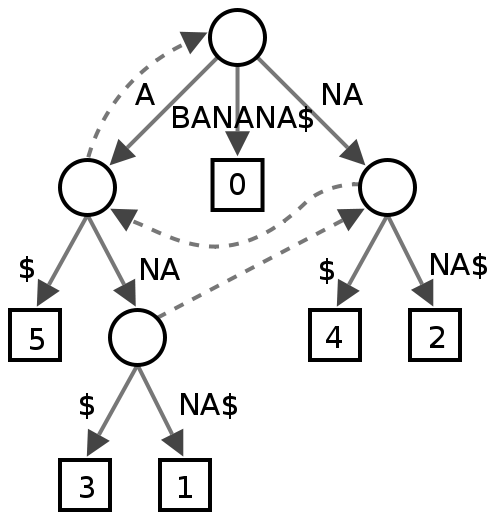
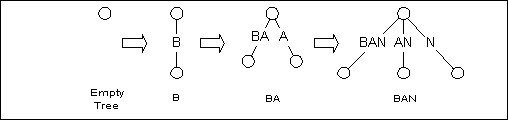
后缀树的构造方法有多种,其中,Esko Ukkonen的算法是由一棵空树开始, 逐步构造T的每个前缀的后缀树. 比如我们构造BANANAS的后缀树, 先由B开始, 接着是BA, 然后BAN, … . 不断更新直到构造出BANANAS的后缀树.
- 应用场景
- 查询字符串S是否包含子串S1。
- 查询最长重复子串
- 查询最长公共子串
- lampel-ziv压缩
- 最长回文
- 反垃圾邮件过滤
- 基于后缀树的分类
-
广义后缀树. 基于多个字符串构建
-
应用规模
- 复杂度
- 构造复杂度. Ukkonen algo O(n)
- 查询复杂度. O(k) k为查询串的长度
####LCA问题
- 概述
LCA问题(Least Common Ancestors,最近公共祖先问题),是指给定一棵有根树T,给出若干个查询LCA(u, v)(通常查询数量较大),每次求树T中两个顶点u和v的最近公共祖先,即找一个节点,同时是u和v的祖先,并且深度尽可能大(尽可能远离树根)。 LCA问题有很多解法, 线段树、Tarjan算法、跳表、RMQ与LCA互相转化等.
- Tarjan算法
- 应用场景:给定一棵有根树,给出若干个查询,每个查询要求指定节点u和v的最近公共祖先。
- 解决思路:
- 在线算法:每次读入一个查询,处理这个查询,给出答案.
- 离线算法:一次性读入所有查询,统一进行处理,给出所有答案.
- 特点:Tarjan算法是离线算法,基于后序DFS(深度优先搜索)和并查集. #####关键词:
- LCA (Lowest Common Ancestor) 最低公共祖先/最长公共前缀
#####参考文献:
- A Suffix Tree Approach To Anti-Spam Email Filtering
- http://blog.csdn.net/v_july_v/article/details/6897097